테크니컬 라이팅과 데이터로써의 글쓰기
테크니컬 라이팅이 AI 시스템이 효과적으로 학습하고 추론할 수 있는 양질의 데이터를 생성하는 과정으로 재정의 될 수 있을까?
이제 '훌륭한' 문서란 AI가 잘 학습할 수 있는 문서가 아닐까? 그렇다면 AI가 잘 학습할 수 있는 문서는 어떤 요소를 갖추어야 할까? AI에게 필요한 테크니컬 라이팅은 뭘까? - 훌륭한 기술 문서, 좋은 테크니컬 라이팅이란 뭘까?
지난 달에 AI가 잘 학습할 수 있는 문서란 무엇일까 고민하면서 여러 가지 시도를 해봤다. 예를 들어, 프론트엔드 챕터 온보딩 문서를 작성하고 이를 AI에 학습시킨 뒤 개발자들이 질문을 할 수 있게 만들었다. 처음에는 이 문서가 AI에게 얼마나 도움이 될지 확신이 별로 없었다. 그런데 점차 AI가 사용자 질문에 더 정확하고 일관된 답변을 제공하는 것을 보고 놀랐다. 심지어 새로 쓴 다른 문서에 있는 정보를 조합해서 코드를 제안하기도 했다.
그래서 어쩌면 복잡하게 생각할 필요없이, 기술 문서가 좋은 학습 데이터일 수 있겠다는 생각이 들었다. 생각해보니 테크니컬 라이팅이 추구하는 글쓰기 원칙이 AI가 학습하기 좋은 학습 데이터의 특징과 연결된 것 같기도 했다. 그래서 테크니컬 라이팅이 AI 시스템이 효과적으로 학습하고 추론할 수 있게 돕는 양질의 데이터를 생성하는 글쓰기가 될 수도 있겠다는 생각이 들었다.
테크니컬 라이팅의 몇 가지 원칙들
테크니컬 라이팅은 직관적으로 이해하기 어려운 기술적 개념을 독자가 쉽게 이해할 수 있도록 설명하는 글쓰기다. 예를 들어 API 통신 방식, 데이터 흐름, 로드 밸런싱 메커니즘 같이 기술적이고 추상적인 정보를 독자가 쉽게 이해할 수 있도록 논리적으로 구조화하고 체계적으로 배열하는 것이 테크니컬 라이팅의 핵심 역할이다. 즉, 일상적으로 또는 현실에서 볼 수 있는 대상이 아니라, 추상화된 기술 개념을 다룬다.
모든 글이 그렇지만, 추상적이고 복잡한 개념을 독자가 이해할 수 있게 만들려면 명확한 구조와 일관된 서술 방식이 특히 더 중요하다. 그래서 테크니컬 라이팅은 정보를 구조화 하고, 선형적이며 순차적인 방식으로 설명하는데 가장 집중한다. 실무에서 늘 염두에 두는 테크니컬 라이팅 원칙 일부를 간단히 소개해 보면 이런 것들이 있다.
먼저, 하나의 문서에서는 하나의 목표만 다룬다. 목차를 구성했을 때 제목이 너무 많거나 섹션의 위계가 너무 깊다면 문서를 분리해야 한다는 뜻이다. 주제도 어려운데 문서가 길고 복잡하면 독자가 길을 잃을 수 있다.
두 번째로, 문서 안에서 구조를 나눌 때는 간단하고 쉬운 것부터 시작해서 점차 세부적인 내용을 소개하는 식으로 작성해서 독자의 인지 부하를 줄인다. 어떤 함수에 대한 설명을 쓸 때를 예로 들어 보자. 짧은 개요라도 다음과 같이 기본적인 기능 소개에서 시작해 어떤 상황에서 사용하면 좋은지로 이어지면 독자가 따라가기 쉽다.

세부적인 정보나 코드에 대한 설명은 이 개요 이후에 작성한다. 독자가 가장 궁금해 할 부분을 먼저 제공하고 논리적으로 필요한 정보를 이어가면 독자가 따라가기 쉽다.
마지막으로, 명확하고 간결한 문장을 쓰기 위해 불필요한 한자어나 번역투를 사용하지 않고 명사 대신 동사를 사용한다. 기술 용어 중 약어는 늘 풀네임을 표기하고, 용어는 일관성 있게 사용한다.
구조화된 문서를 학습하는 AI
이렇게 문장 단위까지 구조화하면, 사람 뿐 아니라 다른 시스템에서도 정보를 검색하고 추출하기 쉽다. 검색 엔진 최적화(SEO)를 지킨 콘텐츠가 검색 시스템에서 먼저 노출되는 것과 같다. AI 시스템에서도 마찬가지다. LLM이 사람이 신뢰할 수 있는 답변을 생성하기 위해 만들어진 RAG(Retrieval-Augmented Generation) 기술을 많이 사용하는 요즘, AI가 답변의 출처로 사용할 수 있는 데이터를 만드는 것이 중요해졌다.
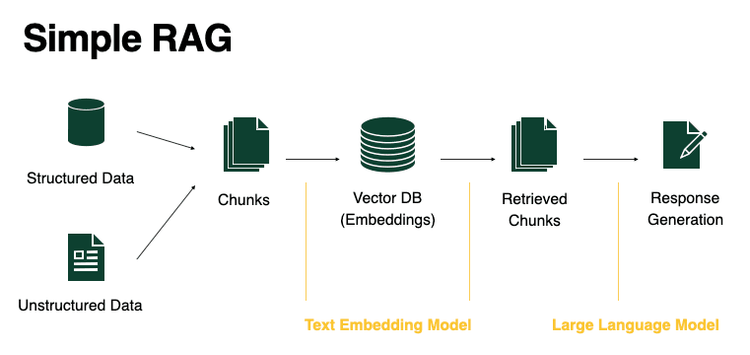
RAG는 검색과 LLM이 결합된 기술이다. 기존 LLM은 최신 정보에 접근할 수 없거나, 특정 주제에 대한 전문성이 부족하거나, 일반적인 주제에 특화되어 있어 환각(Hallucination)이 발생하는 한계가 있었다. RAG는 이런 한계를 보완하기 위해 질문에 관한 정보를 검색하고 검색된 정보를 기반으로 새로운 답변을 생성한다. 그런 뒤 자기 답변에 각주, 즉 출처 문서를 명시해서 답변의 신뢰성을 강조한다.
RAG는 정보를 검색하고 필요한 내용을 정확하게 추출하기 위해 문서를 작은 단위로 나누는 청킹(chunking)과 메타데이터(tagging) 기술을 사용한다.
청킹(chunking)은 문서를 의미 있는 작은 블록으로 분할하는 과정으로, 각 블록은 독립적으로 이해할 수 있는 정보 단위가 된다. 이렇게 분할된 정보는 RAG가 특정 질문에 대한 답을 검색할 때 적합한 정보 블록을 빠르게 찾아낼 수 있도록 돕는다. 예를 들어 API 레퍼런스에서 함수 마다 별도의 문서로 나누어져 있으면 일종의 청킹이 이미 되어 있는 정보이기 때문에 AI는 특정 함수에 대한 질문에 정확하게 답할 수 있다.
메타데이터(tagging)는 문서의 각 청크에 대한 추가적인 정보(예: 제목, 카테고리, 키워드 등)를 제공해서 AI가 문서의 구조와 내용을 더 잘 이해하고 검색 효율을 높일 수 있도록 돕는다. 예를 들어, 문서에 프론트매터(fronmatter) 같은 형식의 카테고리나 키워드 같은 메타데이터가 포함되어 있으면, RAG는 사용자가 어떤 종류의 정보를 원하는지 파악하고 해당 정보를 더 정확하게 제공할 수 있다.
데이터로써의 글쓰기
테크니컬 라이팅은 이해하기 복잡한 기술을 사람이 이해할 수 있는 자연어로 바꿔 설명하는 역할을 해왔다. 그 역할을 위해 (조금은 재미 없지만) 명확성과 구조화를 중심에 둔 글쓰기를 한다. 그런데 이 구조화된 글쓰기가 AI 모델이 학습하기 좋은, 양질의 데이터를 제공한다는 다른 가치도 가질 수 있을 것 같다.
앞으로 사람들이 각자의 지식창고를 만들고, RAG를 거쳐 그 지식을 흡수하게 된다면 어떨까? 어쩌면 테크니컬 라이팅은 인간과 AI 모두에게 유용한 '효과적인 지식 구조화'의 영역으로 역할을 확장할 수 있을 지 모른다. 사람이 이해하기 쉬운 지식과 AI가 이해하기 좋은 데이터는 크게 다르지 않은 것 같다. 더 많은 사람들이 테크니컬 라이팅을 시도해보면 좋겠다.